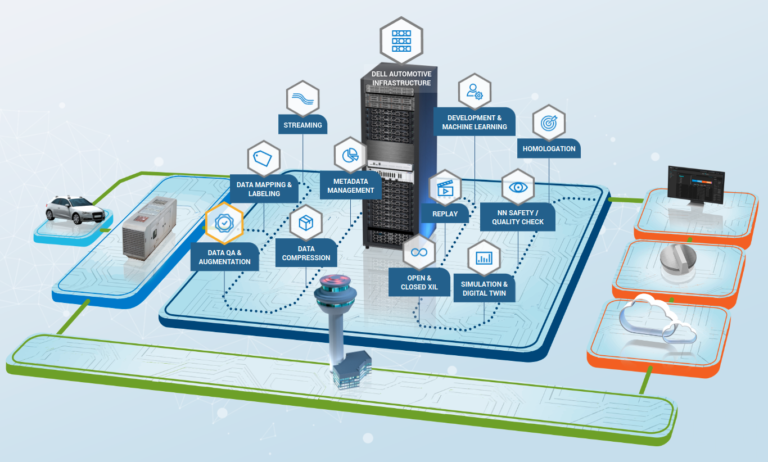
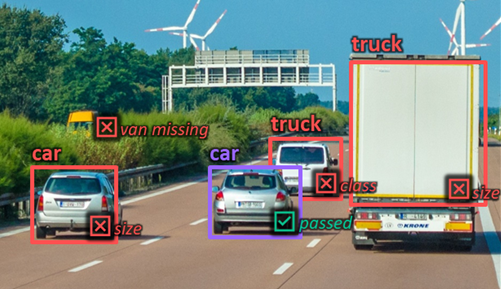
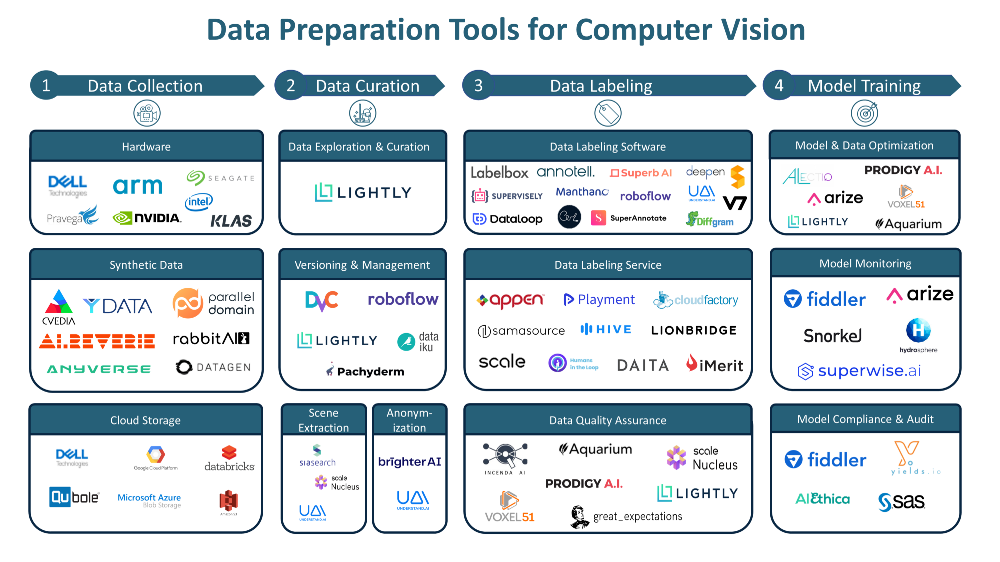
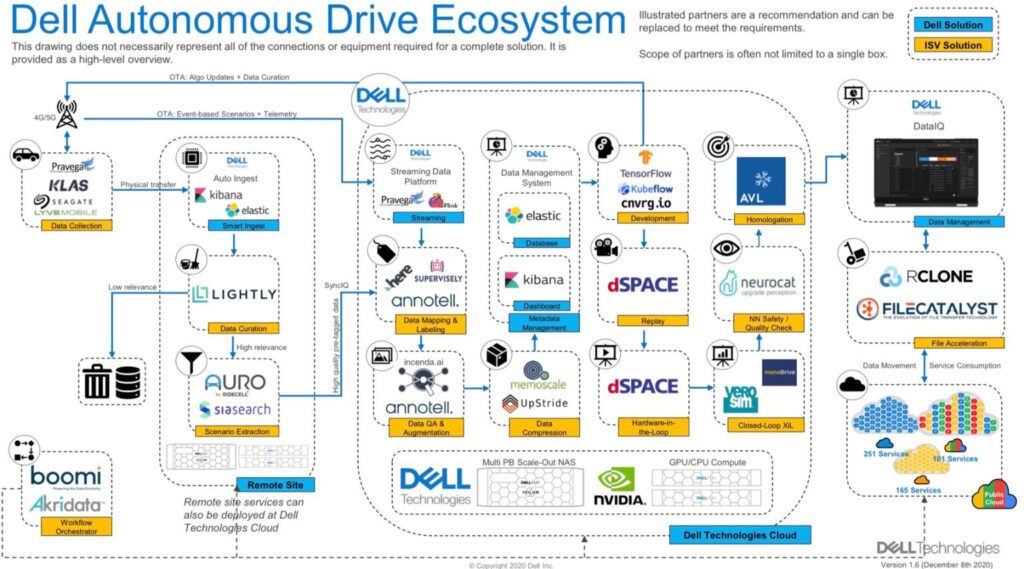
We have partnered with Dell Technologies as a part of a comprehensive, open partner ecosystem for Advanced Driver Assistance Systems / Autonomous Driving (ADAS/AD) development. Incenda AI is part of an ecosystem of vendors selected as best-in-class for ADAS/AD test and development.
This new 3D interactive experience depicts everything from the connected Edge, to a vision of the expansive data pipeline that will be required to enable connected vehicles from the Edge to Core to Cloud, and the ecosystem of automotive AI & software providers that Dell is working with.